Google「Gemma 4」公開——無料で使えるAIが、スマホでもオフラインで動く時代に
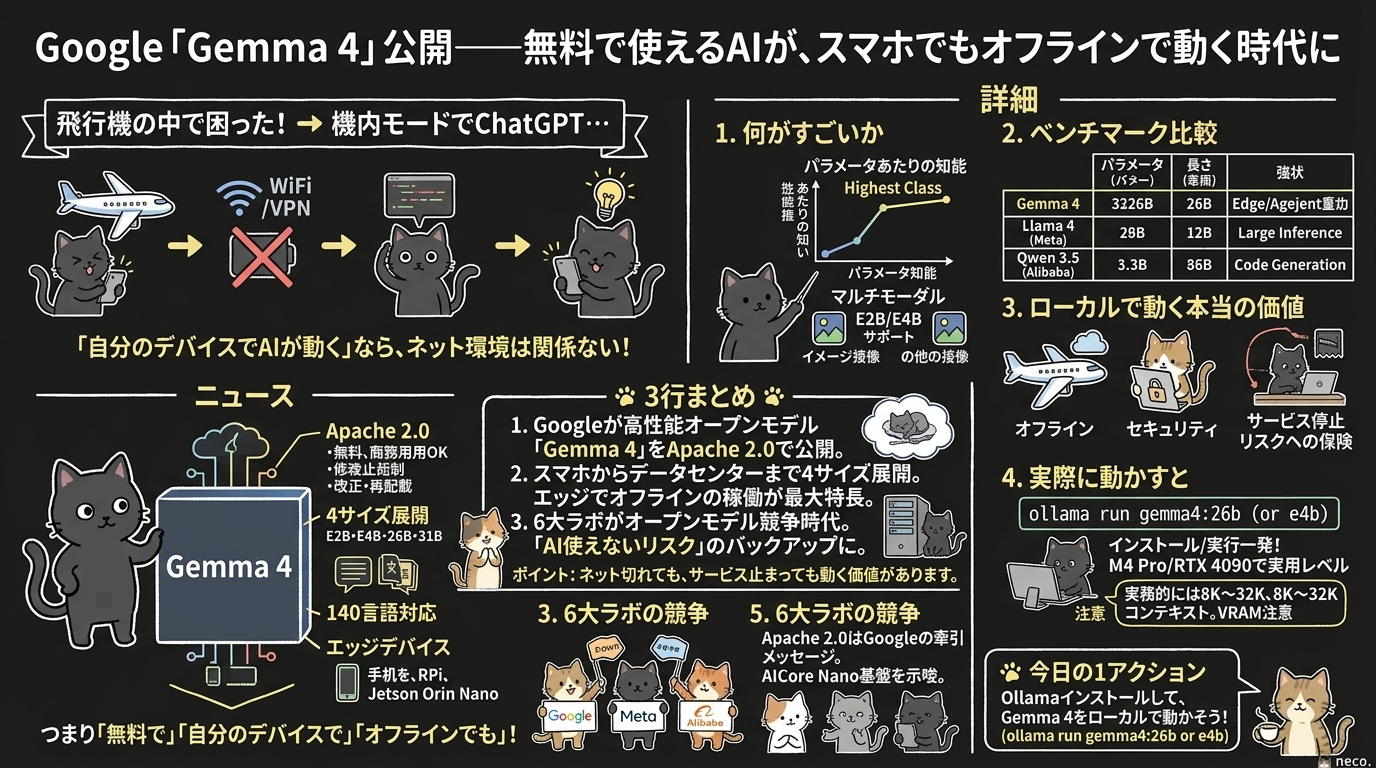
飛行機の中でAIが使えなくて困ったことはないだろうか。
Wi-Fiが不安定、VPNが繋がらない、機内モードでChatGPTは沈黙。
でも「自分のデバイスでAIが動く」なら、ネット環境はそもそも関係ない。
Googleが公開した「Gemma 4」は、その世界を現実に近づけるオープンモデルだ。
ニュース
Google DeepMindが最新のオープンモデル「Gemma 4」をApache 2.0ライセンスで公開した。
Gemini 3と同じ研究技術を基盤に、エージェントワークフロー(AIが自律的にタスクを実行する仕組み)と高度な推論に特化。
E2B・E4B・26B・31Bの4サイズで展開され、140以上の言語に対応。
スマートフォン・Raspberry Pi・NVIDIA Jetson Orin Nanoなどのエッジデバイスでオフライン稼働が可能。
つまり「無料で」「自分のデバイスで」「オフラインでも」使える高性能なオープンAIが手に入った。
3行まとめ
- Googleが高性能オープンモデル「Gemma 4」をApache 2.0(完全自由)で公開。商用利用・改変・再配布すべてOK
- スマホからデータセンターまで4サイズ展開。エッジデバイスでオフライン稼働できるのが最大の特長
- 6大ラボがオープンモデルを競う時代に突入。「AIが急に使えなくなるリスク」へのバックアップとしても価値がある
ポイント
「オープンモデル」という言葉はちょっと馴染みがないかもしれないけれど、要は「誰でも無料で使えるAI」。
ChatGPTやClaudeは月額課金だけど、Gemma 4は無料でダウンロードして自分のPCで動かせる。
ネットが切れても動く。急にサービスが止まっても動く。そこに価値があります。
用語の整理
- オープンモデル(オープンウェイト): AIモデルの重み(学習済みデータ)が公開されていて、誰でもダウンロードして使えるモデル。Apache 2.0ライセンスは商用利用も改変も完全に自由
- エッジデバイス: スマートフォン、IoTセンサー、産業用PCなど、クラウドではなく現場に置かれたデバイスのこと。エッジでAIを動かすことを「エッジAI」と呼ぶ
詳細
1. Gemma 4の何がすごいのか
Gemma 4はGemini 3と同じ技術基盤で作られたオープンモデル。
Google公式によると「パラメータあたりの知能で最高クラス」とされ、高度な推論やエージェントワークフローに最適化されている。
マルチモーダル対応もポイント。全モデルが画像を処理可能で、E2B・E4Bモデルは音声入力にも対応。モデルサイズによって対応モダリティが異なる点は押さえておきたいところ。
2. ベンチマーク比較——他のオープンモデルとどう違うか
2026年4月時点の主要オープンモデル比較がこちら。
| 項目 | Gemma 4 | Llama 4 (Meta) | Qwen 3.5 (Alibaba) |
|---|---|---|---|
| パラメータ | E2B〜31B | 8B〜70B | 0.5B〜72B |
| コンテキスト長 | 128K〜256K(モデル別) | 128K〜512K | 32K〜128K |
| ライセンス | Apache 2.0 | Llama Community | Apache 2.0 |
| 強み | エッジ対応・エージェント特化 | 大規模推論・長文 | コード生成に強み |
※ ベンチマーク数値は各モデルの公式ページを参照してください。モデルの世代更新が速いため、比較は時点に依存します。
Gemma 4の特長は「小さいサイズでも高性能」という点。
2Bモデルはスマートフォンで動かせるサイズで、Qualcomm・MediaTekとの協業によりニアゼロレイテンシー(ほぼ待ち時間なし)を実現している。
3. 「ローカルで動く」ことの本当の価値
「自分のPCでAI動かせる」ことの価値って、AIに詳しい人以外にはピンと来にくいかもしれません。
でも、以下のような場面を想像してみてほしいです。
- 飛行機やオフライン環境: ネットが使えなくてもAIアシスタントが動く
- セキュリティ: 社内データをクラウドに送りたくない場合、ローカルで処理できる
- サービス停止リスク: 最近のようにAIサービスが急に使えなくなるケースへのバックアップ
特に3つ目は現実的な問題として重要度が上がっています。
急にAIが使えなくなったときに、ローカルで動くAIがあるのとないのとでは、業務の継続性がまったく違う。
「保険としてのローカルAI」という考え方は、今後もっと広まるのかなと思います。
4. 実際にローカルで動かしてみると
Ollamaを使うと ollama run gemma4:26b(または軽量な gemma4:e4b)の一発でインストール・実行できます。
M4 ProやRTX 4090程度のマシンなら実用レベルの推論速度が出るという報告が出ている。
ただし、コンテキスト長をフルに使い切ろうとするとVRAM(GPU用メモリ)が足りなくなるケースも。
実務的には8K〜32K程度のコンテキストで使うのが現実的で、「ローカルで動く = いつでも最大コンテキストをフル活用」ではない点は注意が必要です。
5. 6大ラボの「オープンモデル競争」時代
2026年4月時点で、オープンモデルを出している主要ラボは6つ。
Google(Gemma 4)、Meta(Llama 4)、Alibaba(Qwen 3.5)、Mistral(Small 4)など。
オープンモデル同士の性能競争が激化していて、ユーザーにとっては選択肢が急速に広がっている。
Apache 2.0という最も自由度の高いライセンスでの公開は、Googleの「オープンAIエコシステムを自分たちが牽引する」という強いメッセージ。
GoogleのAICore Developer Previewでは、Gemma 4がGemini Nanoの基盤となることが示唆されており、将来のデバイス向けAIとの互換性を見据えた開発が可能になるかもしれない。
今日の1アクション
Ollamaをインストールして、Gemma 4をローカルで動かしてみるのがおすすめです。
ollama run gemma4:26b(または軽い gemma4:e4b)で、自分のPCでAIが動く体験ができます。
ネットが切れても動くAIを手元に置いておく——それだけで「もしも」のときの安心感がかなり変わります。
公式: Google AI Studio / Ollama / Hugging Face
出典
- Gemma 4: Byte for byte, the most capable open models — Google Blog
- Google Releases Open-source AI Model Gemma 4 For Developers — Dataconomy
- Gemma 4 vs Llama 4 vs Qwen 3.5 比較 — oflight.co
著者
neco. 🐈⬛
AI活用コンサル/ITエンジニア歴20年。会社員として400人規模のAIリスキリング研修を統括しつつ、副業で経営者・個人事業主向けにAI導入〜実装をサポート中(経営3年目)。
毎月AIの仕事活用をテーマに勉強会も開催しています。
「AIを"知ってる"から"使える"へ」がモットー。
プロンプト700本以上を無料公開中 → ai-neco
筆者コメント
「オープンモデル」って聞くと開発者向けの印象が強いけど、最近のClaude Code騒動やサービス停止のニュースを見ていると、「急にAIが使えなくなったらどうする?」問題は他人事じゃないんですよね。
ローカルで動くAIを手元に持っておくことは、セキュリティだけじゃなく「業務の保険」としても価値が出てきてると思います。
飛行機とかオフライン環境でも使えるのは、地味だけどかなり助かる場面がありますよね:)