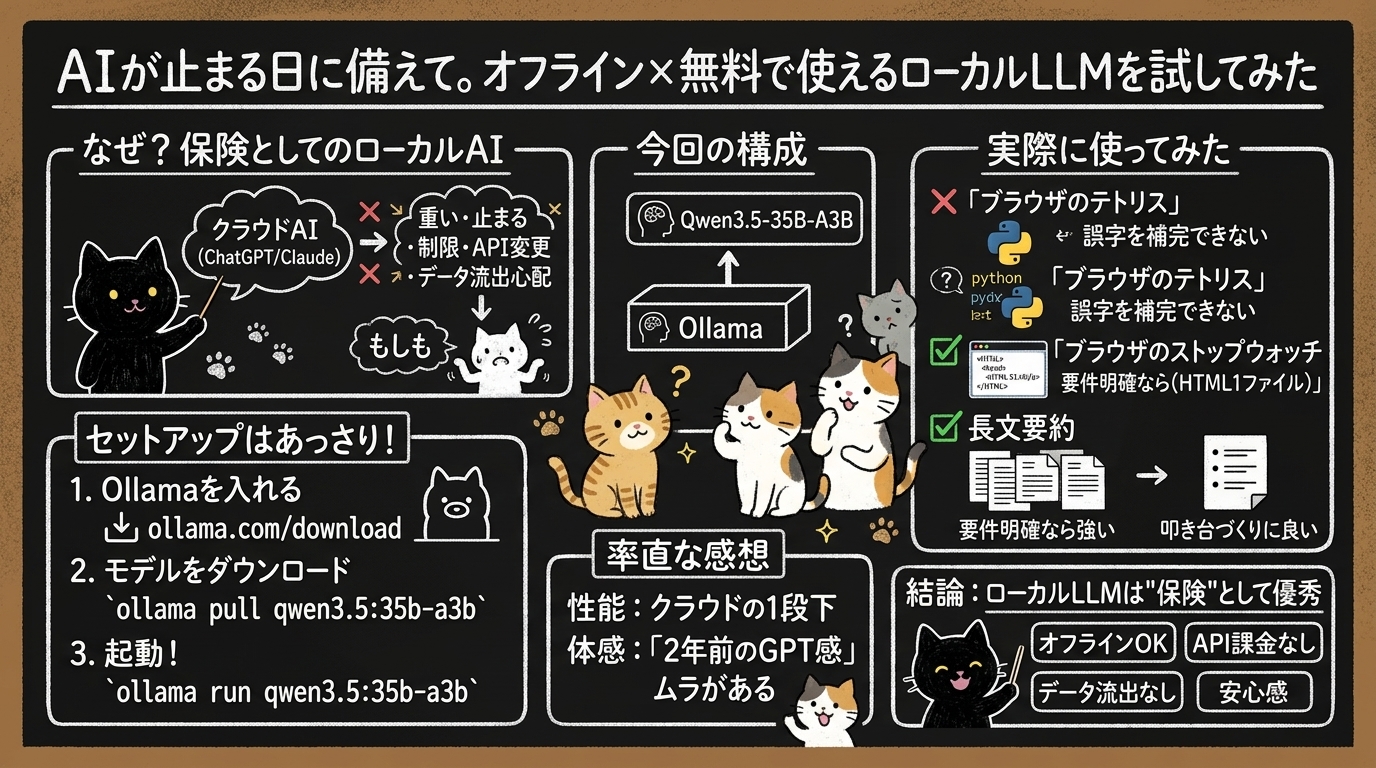
AIが止まる日に備えて。オフライン×無料で使えるローカルLLMを試してみた
最近のAI、めっちゃ便利ですよね!
Claude CodeやCodex、AntigravityみたいなAIエージェントを日常的に使っていると、だんだん**「AIがある前提」**で仕事を組み立てるようになりますよね。
私もかなりそうです。
むしろ最近は、AIなしで考えるほうがしんどいな…と思う場面も増えてきました。
だからこそ、ふと気になることがありました。
クラウドAIが重い日、止まる日、急に使いにくくなる日が来たらどうするんだろう?
もちろん、ChatGPTやClaudeが完全に使えなくなる未来を本気で心配しているわけではないです。
でも、先日Claudeが大規模障害で止まったように、障害や混雑、レート制限、みたいなことは普通に起こります。
またここ最近でも、Claudeが10%価格UP、ChatGPTも価格を見直すという話も出ています。
AIを仕事に組み込んでいる人ほど、「ちょっと使えない」だけでも地味に困っちゃう。
そこで今回は、その**"保険"**として、Ollama上でQwen3.5-35B-A3Bをローカル実行してみました。
でも、手元に置いておく価値はあると感じました。
特に大きいのは、この3つです。
- オフラインでも動く
- 追加のAPI課金なしで使える
- ローカル実行ならデータを外に出さずに使える
この記事は、ローカルLLMの完全な入門というより、普段からクラウドAIを使っている人に向けた「ローカルLLMを試してみた記録」です。
AI初心者さんというよりは、すでにGoogle Antigravity やClaude Code、CodexなどのAIエージェントを使ったことある方向けの記事です。
オタクの皆様だけ、読み進めてください 笑
なぜローカルLLMを使ってみようと思ったのか

私は普段、クラウドAIをかなり使っています。
だからこそ逆に、便利さに少し依存している感覚もあります。
たとえば、こんな場面です。
- ChatGPTやClaudeが重い
- 今日はなんか不安定
- 使いたいモデルに制限がかかる
- APIや料金体系が変わる
- 外に出したくない情報を扱いたい
こういうときに、
「今日はAI使えないか…」で終わるのか
それとも
「じゃあ一旦ローカルの方で回そうか」にできるのか
この差って、思ったより大きい気がしています。
なので今回のテーマは、クラウドAIを捨てる話ではありません。
クラウドAIが使えない日にもゼロにならないための保険を持てるか、という話です(´ ˘ `)♡
今回試した構成
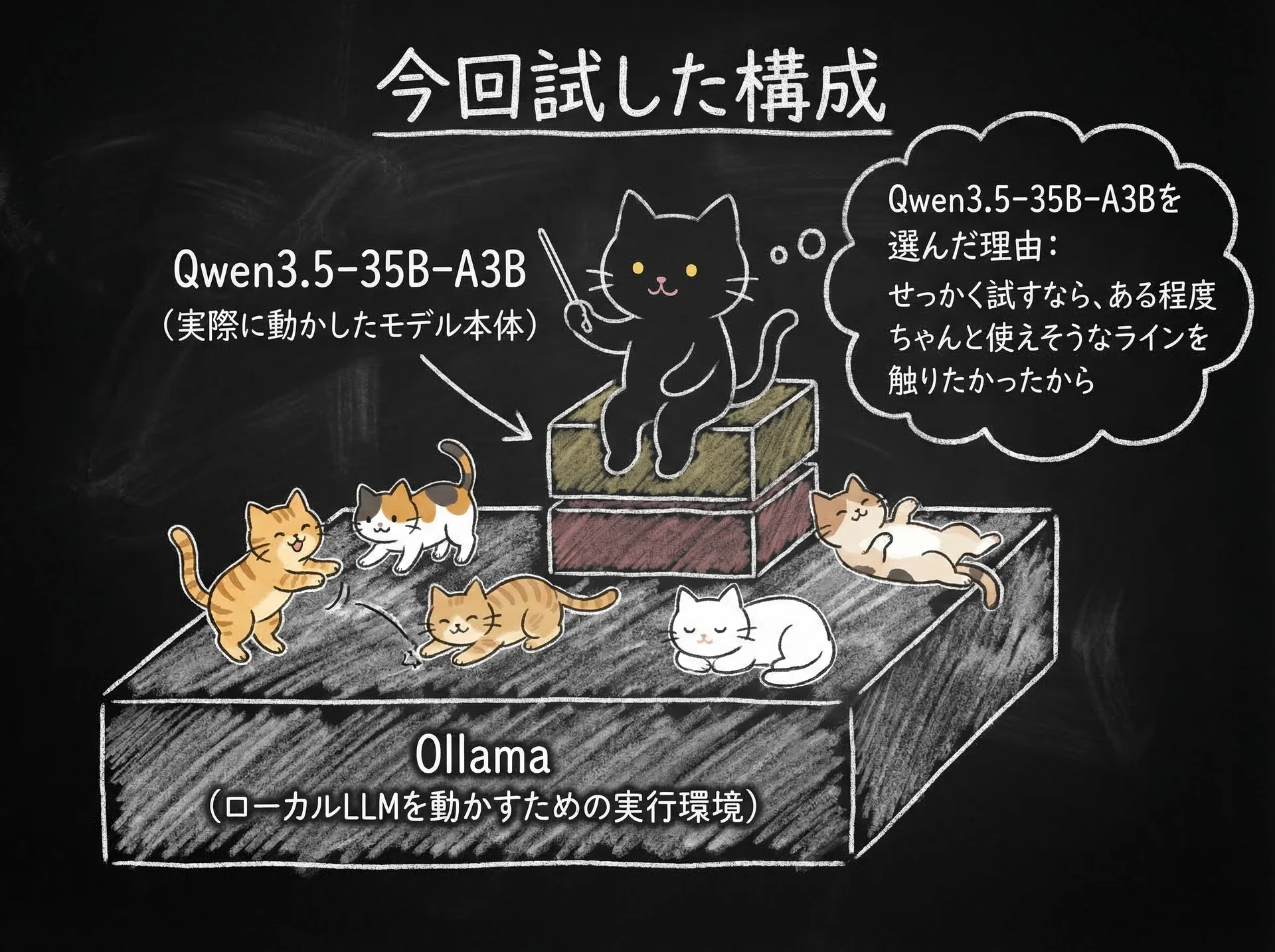
今回私が使ったのは、かなりシンプルです。
-
Ollama
ローカルLLMを動かすための実行環境 -
Qwen3.5-35B-A3B
実際に動かしたモデル本体
要は、Ollamaという土台の上でQwenを動かした、という感じです。
Qwen3.5-35B-A3Bを選んだ理由もシンプルで、せっかく試すなら**「軽いだけ」ではなく、ある程度ちゃんと使えそうなライン**を触りたかったからです。
ローカルLLMって、モデルによっては
「動いたけど、これ実務ではきついな…」
で終わることもあります。
なので今回は、少しでも**"ちゃんと賢い側"**を見に行きました。
セットアップ方法。思ったよりあっさり入る
ここは、正直かなり拍子抜けするくらい簡単でした。
1. Ollamaを入れる
まずはOllamaをインストールします。
公式サイトからインストーラーを入れるだけです。
ollama.com/download にアクセスしてください。
これだけでOllamaのインストールは完了です。
次回以降はOllamaを起動すればOK(macOS/Windowsはアプリ起動、Linuxは ollama serve)。
インストールできたら、ターミナルで確認します。
ollama --version
これでバージョンが返ってくればOKです。
2. モデルをダウンロードする
次に、使いたいモデルをダウンロードします。
ollama pull qwen3.5:35b-a3b
AIエージェントに下記のようにいうだけでもOK
ollamaでqwen3.5:35b-a3bを使えるようにダウンロードして配置してください。
ダウンロード後は、一覧も確認できます。
ollama list
3. 実際に起動する
起動はこれだけです。
ollama run qwen3.5:35b-a3b
これで対話モードに入れます。
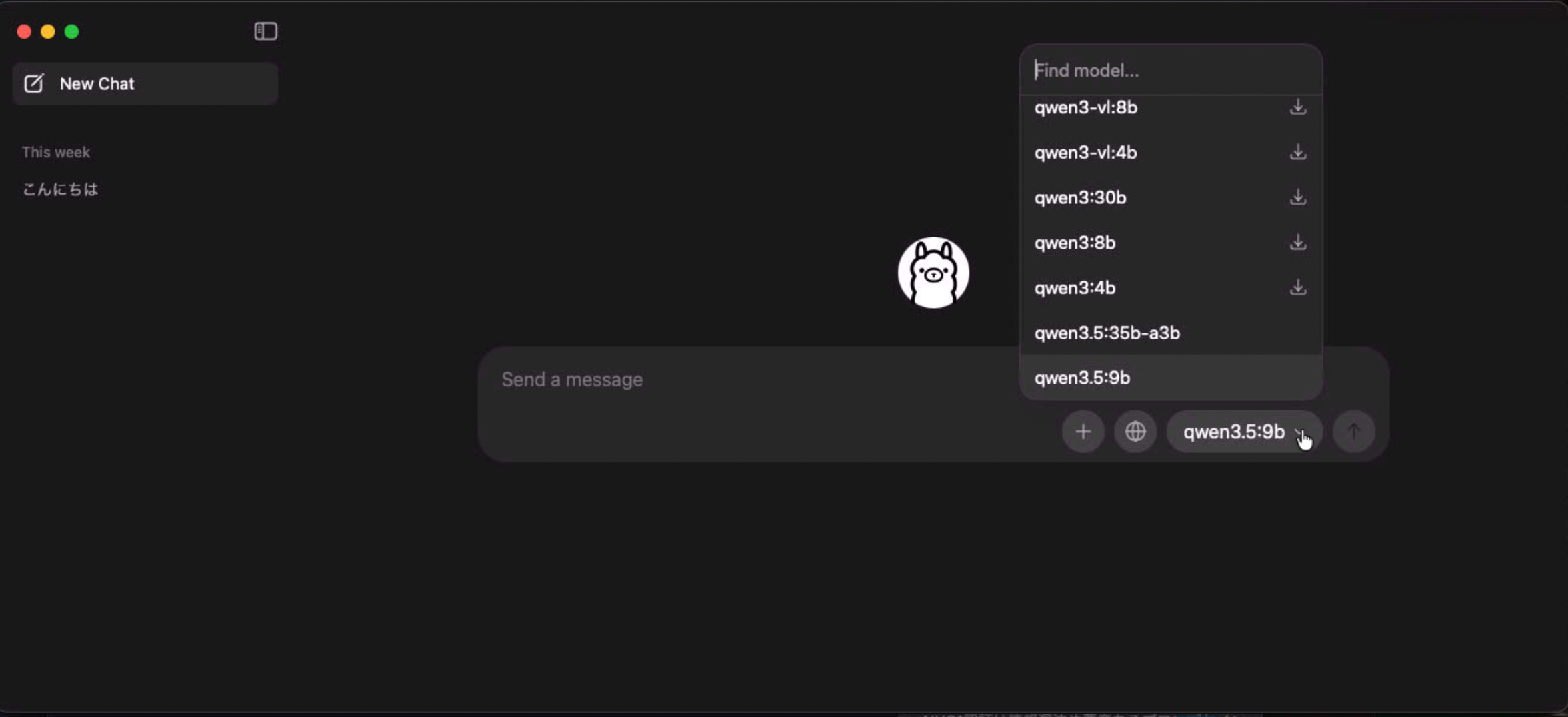
↑こちらのチャットから開始することもできます。
チャット欄右側からqwen3.5:9bを選択し、適当に質問してみてください。
最初は「本当にこれだけ?」という感じなんですが、かなりあっさり動きます。
昔の「ローカルAI」っぽい難しさは、だいぶ薄くなっている印象でした。
まず最初に感じたこと。ちゃんと"自分のPCでAIが動いてる感"がある
これ、言葉にすると当たり前なんですが、体験としては結構違いました。
ChatGPTやClaudeって、当然ながら向こう側で動いているものを使っていますよね。
でもローカルLLMは、自分のマシンの中で動いている。
しかも、初回のダウンロードさえ済ませてしまえばネットがなくても動く。
この安心感は思っていたより大きかったです。
普段クラウドAIを使っていると、
「AIはネットの向こう側にあるもの」
という感覚になりがちなんですが、ローカルLLMはそこを少し変えてくれます。
ベンチマークは強い。でも、そのまま"実戦最強"とは限らない
今回触ったQwen3.5-35B-A3Bは、公開ベンチマークを見るとかなり強いです。
参考:https://artificialanalysis.ai/models/comparisons/qwen3-5-35b-a3b-vs-gpt-5-1
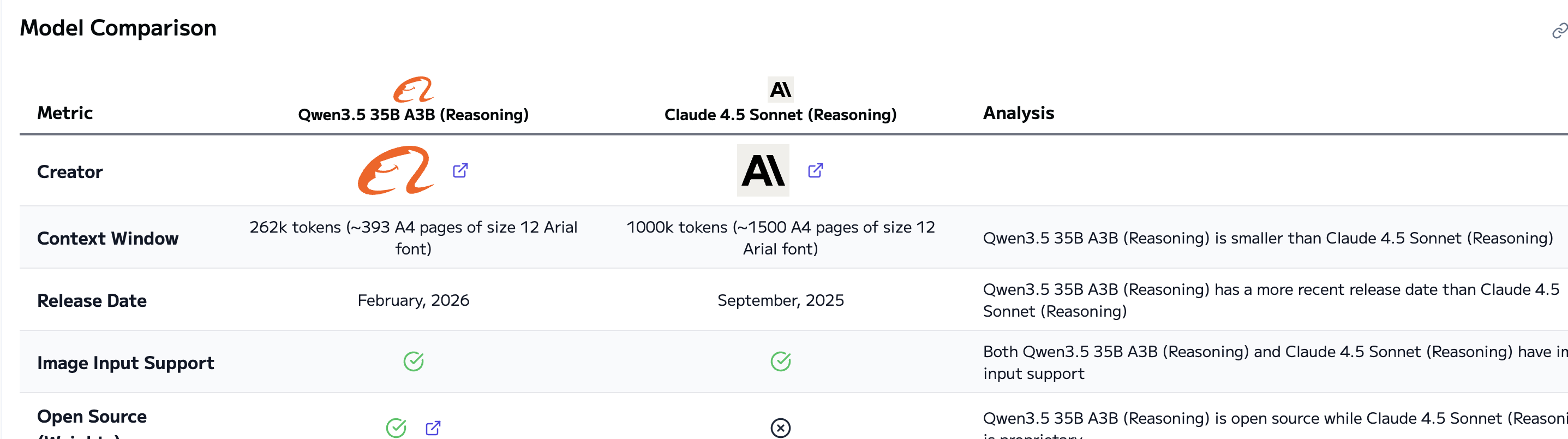
ざっくり比較
モデル概要
| 指標 | Qwen3.5-35B-A3B (Reasoning) | GPT-5.1 (high) | Claude 4.5 Sonnet (Reasoning) |
|---|---|---|---|
| コンテキスト長 | 262k tokens | 400k tokens | 1000k tokens |
| 画像入力 | 対応 | 対応 | 対応 |
| ウェイト | オープン | クローズド | クローズド |
特徴的な評価軸(定性的にまとめ)
| 観点 | Qwen3.5-35B-A3B | GPT-5.1 (high) | Claude 4.5 Sonnet |
|---|---|---|---|
| 推論・知識 | GPT-4〜5世代クラスに近いと評価 | フラッグシップ級 | フラッグシップ級 |
| コーディング | コーディング特化モデル並みに強い指標もあり | 高性能だが詳細非公開が多い | SWE-benchなどで非常に強い |
| マルチモーダル | 多くの公開ベンチで最上位クラス | 強いが詳細スコアは限定的 | Claude 3.5/4.5世代として高評価 |
| オープン性 | Apache 2.0系のオープンウェイト | クローズドSaaS | クローズドSaaS |
| コスパ | Intelligence比で非常に高い | 高品質・中〜高価格帯 | 高品質・高価格帯 |
2026年3月時点でArtificial Analysisなどの比較サイトを見た印象では、オープンウェイトモデルの中でもかなり上位に位置していて、主要なクラウドモデルと比較しても健闘しているように見えました。
ただ、このへんは少しだけ冷静に見たほうがいいなとも感じました。
ベンチマークのセットや重みづけ次第で評価は変わりますし、「クラウド最上位に並んだ」というより「かなり迫っている」くらいのニュアンスが個人的な印象です。
私自身が使ってみた感覚でも、
ベンチではかなり強いけど、実際のWeb開発や長いエージェントフローではクラウドモデルの方が安定している
と感じる場面がありました。
なので私の感覚としては、
Qwen3.5-35B-A3Bは"数字的にもかなり面白いモデル"だけど、"クラウド最上位を完全に置き換える"というより、"ローカルでここまで来たのはすごい"と見るのがしっくりくる、という感じでした。
実際にいくつか試してみた
ここからは、実際に触ってみた所感です。
今回いちばん面白かったのはここでした。
こんにちは!といってみる
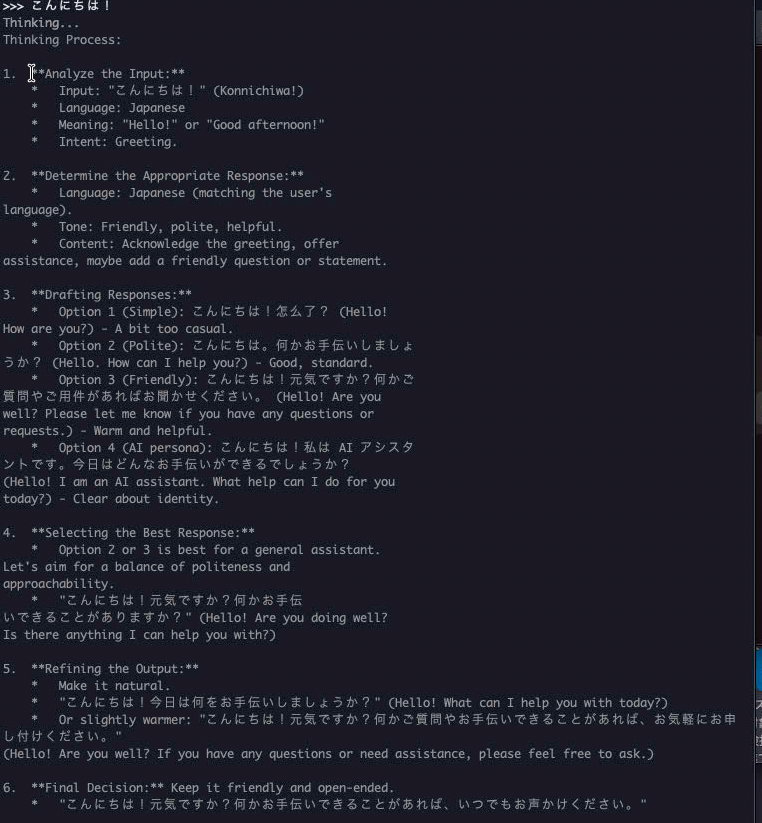
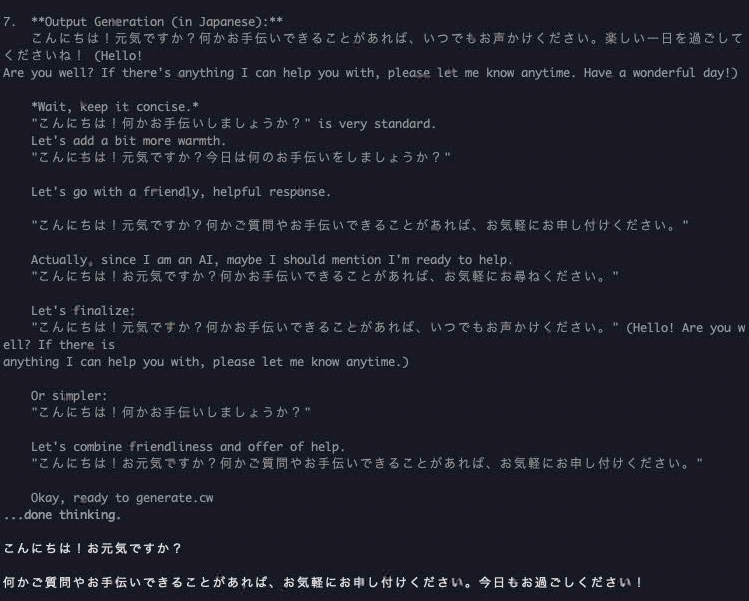
↑グレーはAIの思考
え?そんなに考えます?笑
返答まで1分かかりました...
知識のテスト
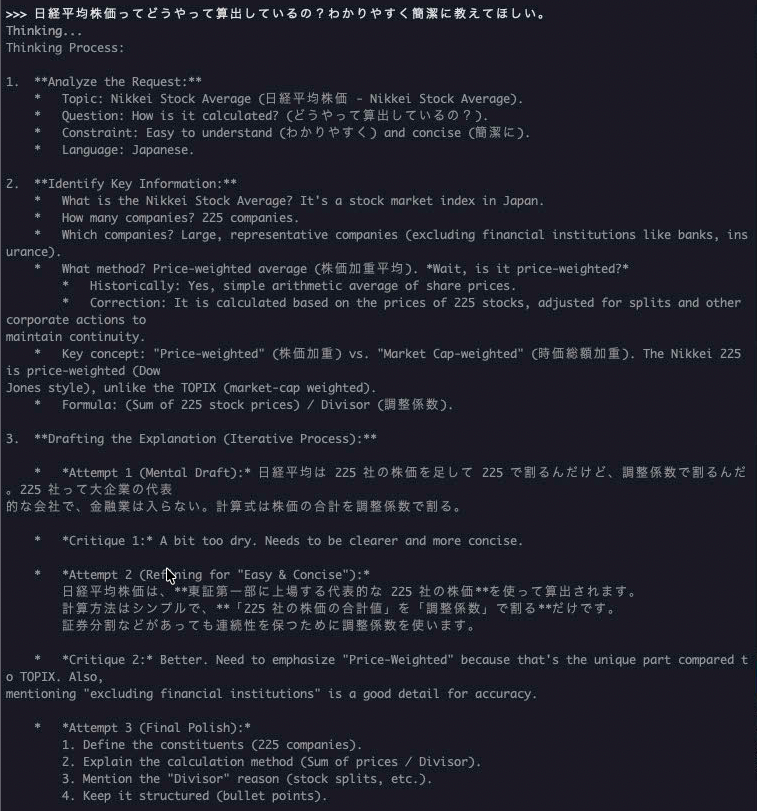
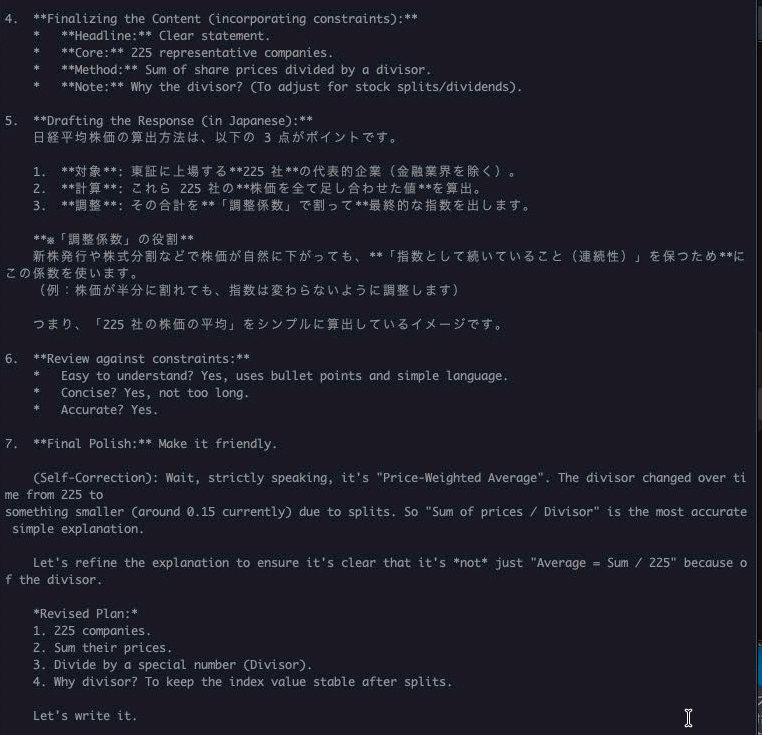
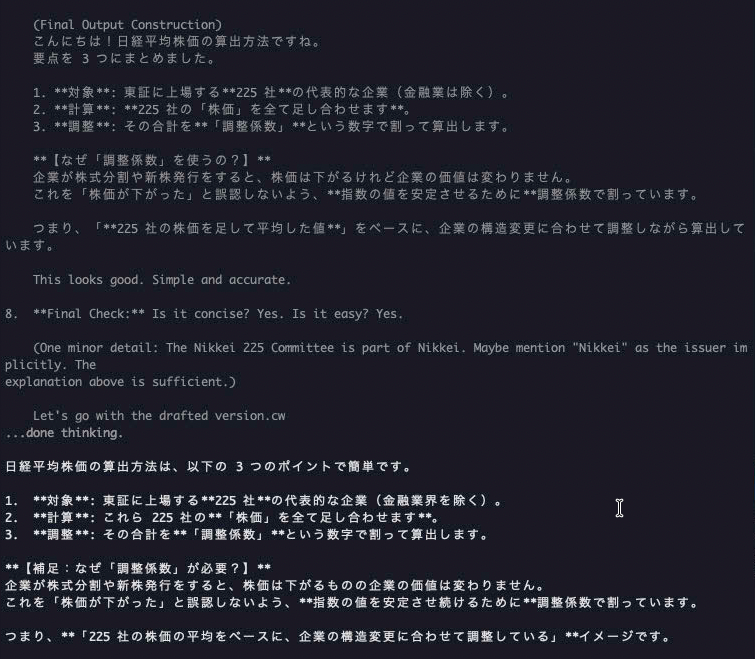
回答は問題なさそうです!
回答まで2分弱...
「ブラウザ上で動くテトリスを作って」は、ちょっとズレた
コーディングテストとして
「ブラウザ上で動くテトリスを作って」
という依頼。
でもタイプミスで、「ラウザ上で動くテトリスを作って」になっちゃった。
こちらとしては、普通にHTML / CSS / JavaScriptのブラウザ実装を想定していたんですが、モデル側はそこをうまく補完できず、Python + Pygame寄りの方向に行きました。
もちろんChatGPTは空気を読んで回答してくれます。
ここで感じたのは、やっぱり
"雑な入力を自然に補完する力"は、クラウド上位モデルの方が強い
ということです。
つまり、ローカルLLMは全部ダメというより、
曖昧さや誤字を飲み込んで一発で正解に寄せる力は、まだ少し弱い。
これはかなり象徴的でした。
「ブラウザで動くストップウォッチ。HTML1ファイルで」はかなり素直だった
次に、
「ブラウザで動くストップウォッチ作って。HTML1ファイルで」
と投げてみました。
これはかなり良かったです。
ちゃんとブラウザ用の単一HTMLで返してきて、構成も素直でした。
この差が面白くて、ローカルLLMは「賢くない」というより、
要件が明確なタスクにはちゃんと強い
んですよね。
逆に、曖昧さを含む依頼になるとズレやすい。
このへんはかなり使いどころが見えるポイントでした。
長文要約は思ったよりかなり良かった
さらに、長めの文章を渡して
「3行で要約して。事実と意見を分けて」
みたいなことも試しました。
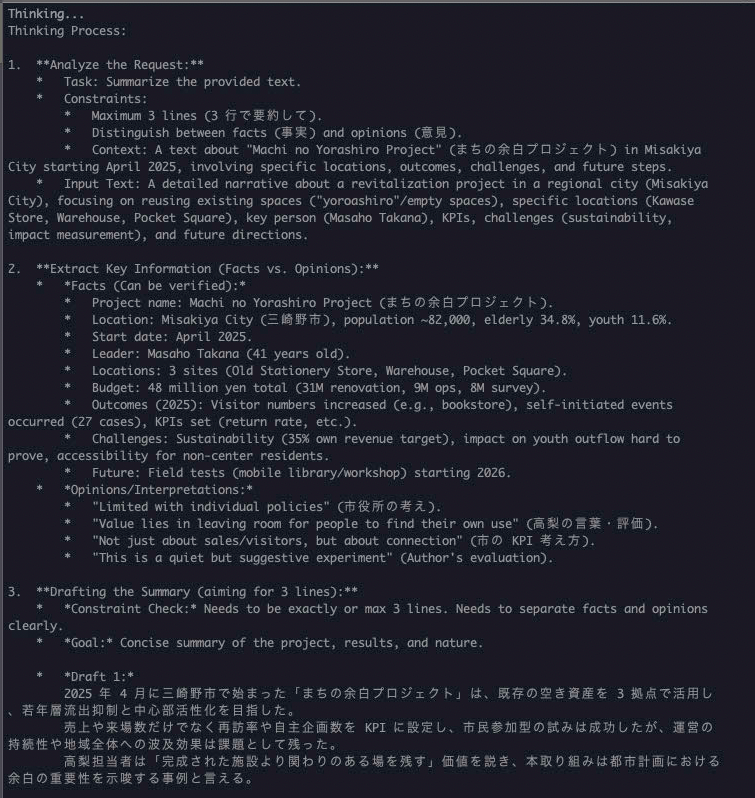
↑上記の5倍ぐらい考えて、下記の通り出力してくれました

ここは正直、意外と良かったです。
もちろん細かく見ると丸め方が少し雑なところはあるんですが、全体としてはかなり実用的な要約になっていました。
この結果を見て、ローカルLLMは意外と
- 要約
- 情報整理
- 下書き
- 叩き台づくり
- 壁打ち
みたいな用途にはかなり相性がいいな、と感じました。
ちょっと気になったところ。考えすぎる
一方で、少し気になったのはThinkingモードで考えすぎる場面があることです。
たとえば、入力が不足しているときや、
「3行で」「事実と意見を分けて」みたいに形式条件があると、内部でかなり丁寧に自己確認し続けることがあります。
最終的には答えにたどり着くんですが、体感としては
「真面目すぎて収束が遅い」
みたいな感じでした。
このへんは、ローカルLLMが壊れているというより、
軽いタスクにも全力で考えにいくせいで、少し空回りする印象です。
なので使ってみた所感としては、
タスクに応じて Thinking の有無を切り替える
みたいな運用がいいかもなぁと思いました。
使ってみた私の率直な感想
ここはかなり正直に言うと、
最前線のクラウドモデルより一段下です。
一発で意図を汲む感じとか、
雑に投げてもそれっぽく仕上げてくれる感じとか、
そのあたりはやっぱりChatGPTやClaudeの方がもちろん強い。
体感でいうと、
「2年前くらいのGPT感」
というのがいちばん近いかもしれません。
当たるときはかなり良い。
でも、ムラがある。
そして外したときは少しズレが大きい。
ただ、ここで終わらないのがローカルLLMの面白いところです。
でも、追加課金なしでローカルで動くなら話は変わる
性能だけを比べたら、そりゃクラウド上位モデルの方が強いです。
でも、ローカルLLMは評価軸がちょっと違います。
- 追加のAPI課金なしで使える(端末と電力さえあればOK)
- オフラインでも動く
- データを外に出さない
- 何回でも試せる
- "手元に自分のAIがいる"感覚がある
この条件が乗ると、かなり魅力的に見えてきます。
特に、壁打ちとか、社内メモ整理とか、ラフな下書きとか、
**「最終成果物ではないけど、AIに手伝ってほしい仕事」**って結構あるんですよね。
そこを全部クラウドに投げなくてもいい。
そう考えると、ローカルLLMはかなり現実的です。
私の所感。ローカルLLMは"代替"ではなく"保険"・"選択肢の1つ"

今回触ってみて、いちばんしっくりきたのはこれでした。
ローカルLLMは、ChatGPTやClaudeの代わりではない。
でも、使えない日が来てもゼロにならないための"保険"としてはかなり優秀。
しかも、その保険は非常用なだけじゃなくて、日常の軽い仕事にもちゃんと使えます。
これが思っていたより良かったです。
クラウドAIを捨てる必要はまったくないと思います。
むしろ、そこは引き続き使えばいい。
でもそれとは別に、
自分のPCの中に、自分で動かせるAIを一つ持っておく。
この感覚は、思っていた以上に安心感がありました。
まとめ
今回、Ollama上でQwen3.5-35B-A3Bを動かしてみて、ローカルLLMに対する印象はかなり変わりました。
正直、もっと「お試し止まり」かなと思っていたんですが、実際にはちゃんと使いどころがある。
もちろん、最前線のクラウドモデルの代わりにはなりません。
でも、
- オフラインで動く
- 追加のAPI課金なしで回せる
- データを外に出さない
- AIが止まる日に備えられる
この価値はかなり大きいです。
私の結論はシンプルです。
AIを日常的に使う人ほど、ローカルLLMは一度触っておいて損はない。
クラウドAIの代替としてではなく、
"手元にある保険"として。
関連リンク
著者
neco. 🐈⬛
AI活用コンサル/ITエンジニア歴20年。会社員として400人規模のAIリスキリング研修を統括しつつ、副業で経営者・個人事業主向けにAI導入〜実装をサポート中(経営3年目)。
毎月AIの仕事活用をテーマに勉強会も開催しています。
「AIを"知ってる"から"使える"へ」がモットー。
プロンプト700本以上を無料公開中 → ai-neco