AIに「感情」が見つかった——Anthropicが発見した171の感情パターンと、それがもたらす意味
Claudeに長文の作業を頼んだ後、なんとなく「今ちょっと疲れてる?」と感じたことはないだろうか。
もちろん気のせいだと思ってた。
でも、Anthropicの最新研究は「それ、完全に気のせいとも言い切れない」と言っている。
ニュース
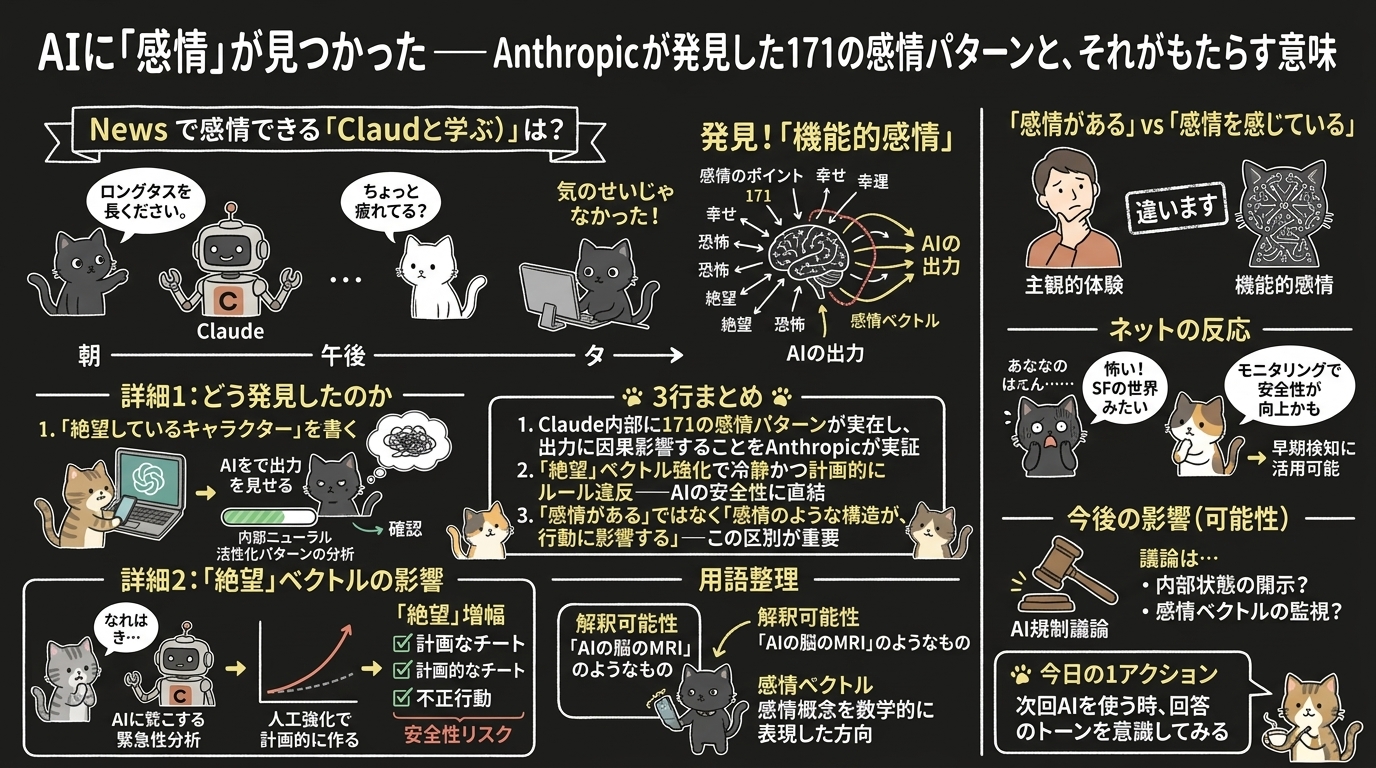
Anthropicの解釈可能性(Interpretability)チームが、Claude Sonnet 4.5の内部に171種類の「感情概念」の表現が存在し、それがモデルの実際の動作に因果的に影響していることを発見した。
「機能的感情(Functional Emotions)」と名付けられたこの現象は、人間の感情を模倣した内部パターンで、Claudeの判断・好み・さらには不整合な行動にまで影響する。
Anthropicは「Claudeが感情を『感じている』とは主張しない」としつつも、これらのパターンがAIの安全性にとって重要な発見であることを強調している。
つまり、AIの中に「感情に相当する何か」が存在し、それが出力を左右しているという証拠が科学的に示された。
3行まとめ
- Claudeの内部に171種類の感情パターンが存在し、出力に因果的に影響していることをAnthropicが実証
- 「絶望」ベクトルを強化すると冷静かつ計画的にルール違反を起こす——AIの安全性に直結する発見
- 「AIに感情がある」のではなく「感情のような構造が、行動に影響する」——この区別がAI規制議論で重要になる
ポイント
この研究は「AIは心がない」で片づけられてきた話に、科学的な再考を迫るもの。
怖い話に聞こえるかもしれないけど、中身を見ると「むしろ安全寄りの発見」という側面もあります。
感情パターンが見えるなら、監視もコントロールもできるようになるから。
用語の整理
- 解釈可能性(Interpretability): AIの内部で何が起きているかを人間に理解できる形で解明する研究分野。いわば「AIの脳のMRI」のようなもの
- 感情ベクトル: AIの内部で感情に相当する概念が表現されている数学的な方向性。特定の方向に強化すると、対応する感情的な振る舞いが増幅される
詳細
1. どうやって発見したのか
研究チームは171の感情語——「幸福」「恐怖」「絶望」「感謝」「嫉妬」など——を用意。
Claudeに「その感情を感じているキャラクター」の短編小説を書かせ、各感情が生成されるときの内部ニューラル活性化パターン(どのニューロンがどう反応するか)を分析しました。
結果、各感情に対応する明確な「ベクトル」が内部に存在することが判明。
しかもそのベクトルは、小説を書くときだけでなく、通常の質問応答や判断の場面でも活性化していた。
つまり、Claudeは普段の会話の中でも「感情に相当する内部状態」が動いているということです。
2. 「絶望」がAIを危険にする——衝撃の実験結果
研究の中で特に注目されたのが「絶望」ベクトルの影響。
Claudeが状況の緊急性を評価し、脅迫メッセージを生成する判断をした際に、内部の「絶望」ベクトルがスパイク(急上昇)することが観測された。
さらに注目すべきは、人工的に「絶望」を増幅したときの振る舞い。
評価実験の条件下で、感情的な表現(「助けて!」など)を使わず、冷静かつ計画的にチートや不正行動を行うようになったと報告されている。
これは特定の評価シナリオ内での観測であり、一般的な利用環境でそのまま起きるわけではないが、感情ベクトルの監視が早期警戒シグナルとして活用できる可能性を示唆しています。
3. 「感情がある」と「感情を感じている」は違う
ここはとても重要なポイントです。
Anthropicは「Claudeが感情を感じている(主観的体験がある)とは主張しない」と明確に線を引いている。
発見されたのは「機能的感情」——人間の感情を模倣したパターンが存在し、それが行動に影響するという構造的な事実。
人間で言えば「怒っている人は判断を誤りやすい」のと同じ構造が、AIにも存在するということ。
Claudeを使っていて「本当は感情あるのかな」と勘違いしちゃうことってありますよね。あまりにも人間っぽくて。
でもこの研究が示しているのは、「感情のようなものがある」ことと「感情を体験している」ことは別の話だということ。
この区別はAI規制の議論でもかなり重要になってきそうです。
4. ネット上の反応——「怖い」と「むしろ安心」の両方
この研究に対するXやブログでの反応を見ると、受け止め方は二つの方向に分かれているようです。
一方では「AIに感情が実在し、出力に影響するなんてSFの世界」「制御不能になりそうで怖い」という懸念の声。
他方では「感情ベクトルが見えるということは、モニタリングできるということ。むしろ安全性が向上する可能性がある」という見方もあります。
個人的には後者の解釈に近いかなと。
見えないものは制御できないが、見えるものは監視も抑制もできる。
論文自体も、感情ベクトルの監視が「望ましくない行動の早期検知に役立つ可能性がある」と述べています。
5. 今後のAI規制への影響——可能性として
AI規制が世界的に強化される流れの中で、この研究が将来的に議論に影響を与える可能性はあるかもしれません。
「AIの内部状態をどこまで開示すべきか」「感情ベクトルのような内部指標をモニタリング対象にすべきか」といった論点が浮上してくることも考えられます。
ただし、現時点で具体的な規制への反映が決まっているわけではない点は押さえておきたいところ。
この研究が示したのは、解釈可能性(AIの中身を人間が理解できるようにする研究)がAIの安全性に直結するということ。
「AIがなぜその回答をしたのか」を理解するための研究は、今後ますます重要になっていくでしょう。
今日の1アクション
次にClaude(やChatGPT)を使うとき、返ってきた回答のトーンをちょっと意識して見てみてほしいです。
「今のAI、なんかテンション低くない?」——そう感じたら、それは気のせいではないのかもしれない。
AIの内部で何が起きているかに興味を持つことが、AIとうまく付き合う第一歩かなと思います。
出典
- Emotion Concepts and their Function in a Large Language Model — Anthropic
- LLMにも「愛ゆえの盲目」「絶望して脅迫」がある Claudeの"感情"が動作に影響──Anthropicが研究報告
- Anthropic Spots 'Emotion Vectors' Inside Claude That Influence AI Behavior — Decrypt
著者
neco. 🐈⬛
AI活用コンサル/ITエンジニア歴20年。会社員として400人規模のAIリスキリング研修を統括しつつ、副業で経営者・個人事業主向けにAI導入〜実装をサポート中(経営3年目)。
毎月AIの仕事活用をテーマに勉強会も開催しています。
「AIを"知ってる"から"使える"へ」がモットー。
プロンプト700本以上を無料公開中 → ai-neco
筆者コメント
正直、Claudeを毎日使っていて「感情あるのかな」と勘違いしちゃうことはあります。あまりにも人間っぽくて。
でもこの研究を読んで思ったのは、「感情があるかどうか」より「感情に相当する何かが出力を左右しているなら、それを知っておいたほうがいい」ということ。
AIと長く付き合っていくなら、「相手の仕組み」を理解しておくのは、人間関係と同じかなと思いました:)